
게시판의 하단에는 위의 이미지와 같이 몇 페이지부터 몇 페이지까지 있는지 볼 수 있다.
그렇다면 이러한 페이징을 하기 위해선 어떤 것을 알아야 할까? 바로 현재 페이지의 위치, 총 페이지 수이다.
총 페이지 수란, 보통 (조회된 모든 데이터 수) / (한 페이지에서 보여줄 글 수) 를 말한다.
그 말은, 위의 이미지처럼 1페이지에서 2페이지, 3, 4, 5 넘어갈 때 마다, 이전에 조회되었던 데이터를 함께 조회해야하는 것이다. 하지만 이전에 조회된 데이터는 사용하지도 않는다.
그냥 뒤에 있는 데이터를 탐색하기 위해 어쩔 수 없이 조회되는 데이터인 것이다.
보통 내가 진행했던 프로젝트는 뭐 게시글이 천만개~1억개 정도는 되는 것이 아니라서 매번 총 데이터의 수를 조회해도 상관없었지만, 실제 현업에서 프로젝트를 진행한다면 위의 방식이 성능 부분에 있어서 많은 손해를 일으킬 수 있다.
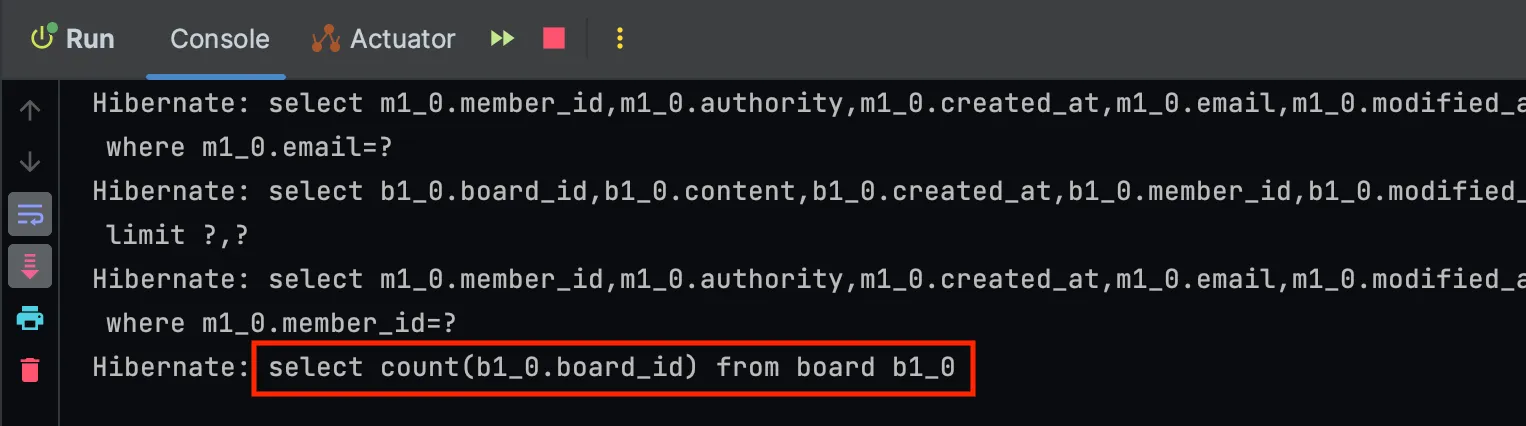
JPA에서 Page 클래스를 사용해 데이터를 조회할 땐, 반드시 전체 데이터 수를 조회하는 쿼리가 실행된다.

그 이유는 Page 클래스 내부에 getTotalPages()라는 전체 데이터 개수를 조회하는 메서드가 있기 때문이다.
그래서 이 글에선 아래의 두 가지 방법을 모두 구현해 볼 것이다.
- Page 객체를 사용하지 않고 페이징 구현
- Offset 없이 페이징 구현
참고로 두 가지 방법을 모두 구현하는 이유는, 가장 마지막에 있는 UI 정책 때문에 Offset 없이 페이징 구현 방법은 사용이 불가능할 수 있기 때문이다.
Page 객체를 사용하지 않고 페이징 구현
첫번째는 엔티티의 리턴타입을 Page가 아니라 List로 해볼 것이다.
내가 사용하는 조회 메서드는 페이징된 Board 엔티티 그대로 리턴하기 때문에 리턴 타입을 Page에서 List로 변경하고 @Query 어노테이션을 추가해줬다.
쿼리를 직접 추가해준 이유는 Spring JPA는 기본적으로 Page를 리턴할 때 페이징을 자동으로 처리해준다. 하지만 List를 리턴할 경우 데이터 전체를 조회하기 때문에 직접 쿼리로 명시해줘야 한다.
@Repository
public interface BoardRepository extends JpaRepository<Board, Long> {
@Query(value = "SELECT b FROM Board b")
List<Board> findBoardWithOutCount(Pageable pageable);
...
}
참고로 메서드의 파라미터에 Pageable 클래스만 넣어주면 아래의 로그를 보다시피 알아서 페이징 처리가 된다.
SELECT
b1_0.board_id, b1_0.content, b1_0.created_at, b1_0.member_id,
b1_0.modified_at, b1_0.title, b1_0.views
FROM
board b1_0
ORDER BY
b1_0.board_id DESC
LIMIT ?, ?;
List로 리턴 타입을 변경한 뒤, 테스트를 해본 결과 아래와 같다.
리턴 타입이 Page인 경우
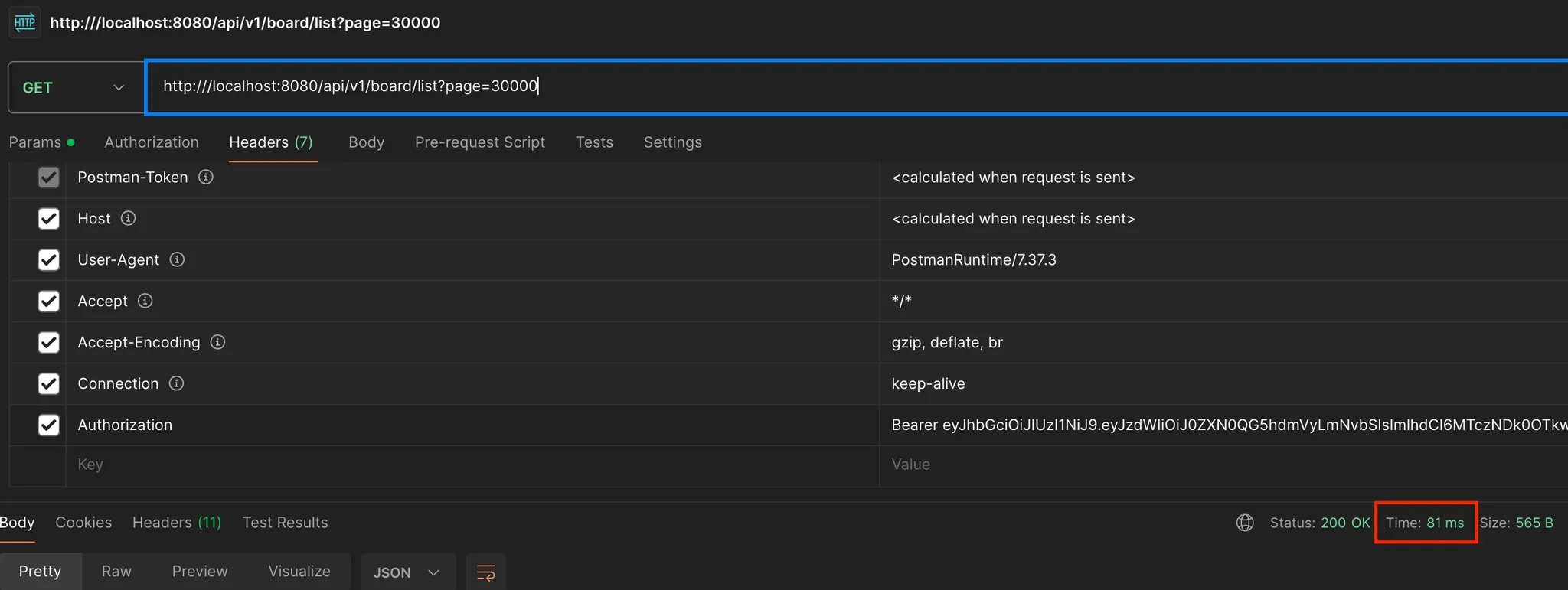

Page를 리턴 타입으로 사용했기 때문에 count 쿼리가 실행되었다.
리턴 타입을 List으로 변경한 후

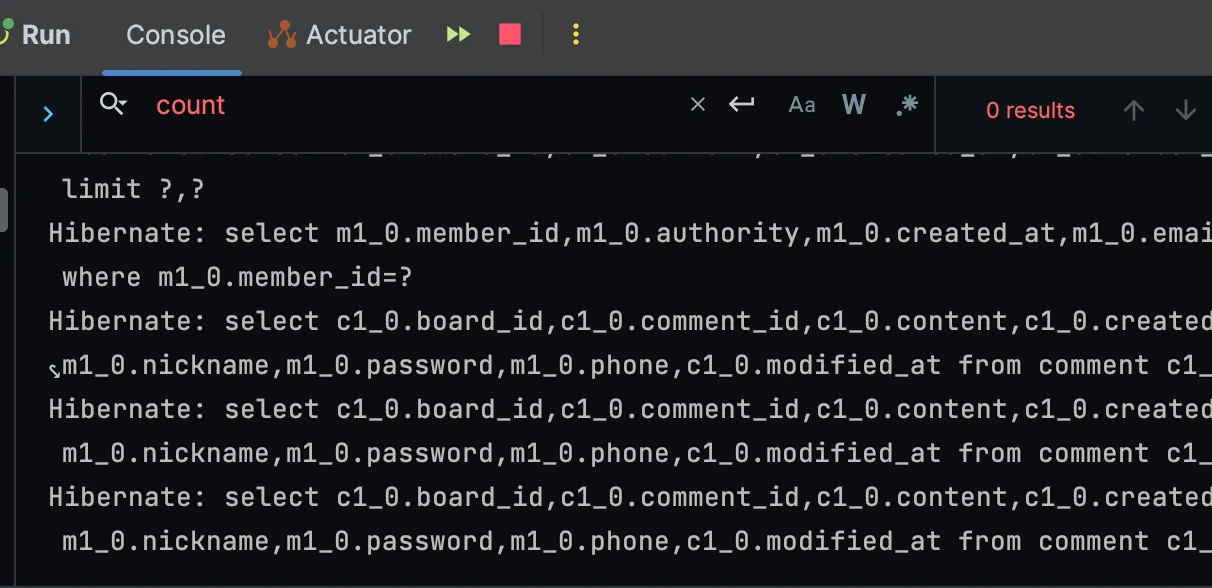
리턴 타입을 List으로 변경한 경우 로그를 확인한 결과, count 쿼리가 실행되지 않았다.
또한 실행 시간도 81ms에서 62ms로 단축되었다.
굉장히 미세한 변화다… 그래도 시간은 확실하게 줄어서 다행이다!
하지만 이 방법을 사용해도 Offset은 아래의 로그와 같이 동일하게 사용된다..

Offset 없이 페이징 구현
SQL에서 Offset이란 조회할 데이터의 시작점을 의미한다.
SELECT
b1_0.board_id, b1_0.content, b1_0.created_at, b1_0.member_id,
b1_0.modified_at, b1_0.title, b1_0.views
FROM
board b1_0
ORDER BY
b1_0.board_id DESC
OFFSET 1 LIMIT 5
위의 쿼리를 실행하면 Board 테이블의 데이터를 board_id 컬럼을 기준으로 내림차순 정렬 하는데, 그 중 1번째 데이터부터 5개를 조회할 수 있다.
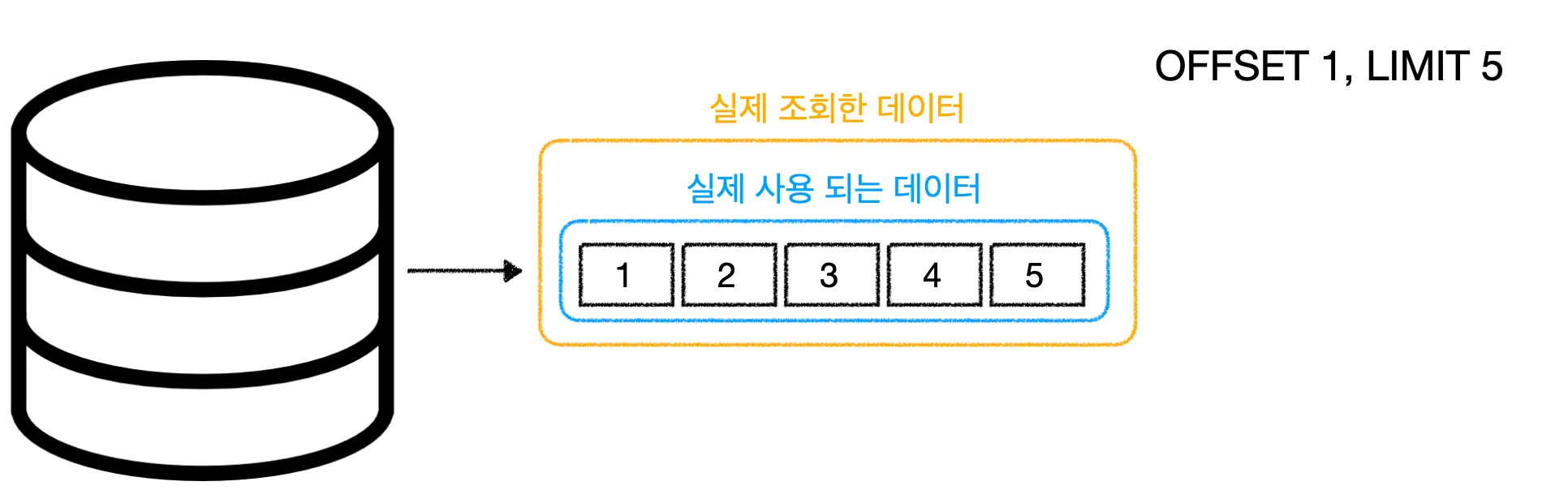
이처럼 적은 양의 데이터를 조회할 땐, 성능에 크게 문제가 발생하지 않는다.
하지만 Offset 값이 100이 아니라 1,000,000처럼 매우 큰 값이라면 어떻게 될까?
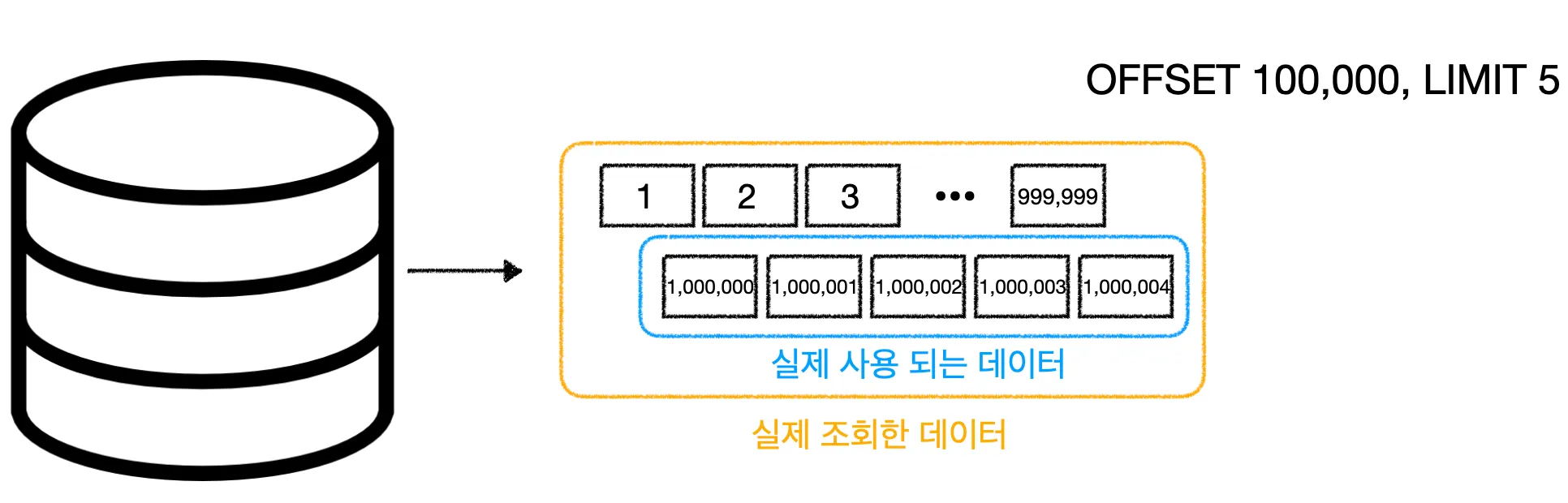
예를 들어, 내가 필요한 데이터는 1,000,000번째부터 1,000,005번째까지의 데이터인데, 이 데이터를 조회하기 위해 데이터베이스는 1부터 999,999번째 데이터까지 모두 스캔한 뒤 무시해야 한다. 결국 사용하지도 않을 데이터를 조회하는 비효율적인 작업이 발생하게 되는 것이다.
만약 저 Offset 방식을 사용하지 않으면 지연 시간이 더 눈에 띄게 줄지 않을까? 한번 Offset 없이 페이징 처리를 구현해봅시다.
BoardRepository
많은 개발자들이 사용하는 No Offset 구현 방법은, Board 엔티티의 PK를 사용해 PK 보다 작은 데이터 X개를 조회하는 방법이다.
왜냐하면 보통 PK는 엔티티가 데이터베이스에 추가된 순서대로 저장되기 때문이다. 자연스럽게 게시글이 작성된 시간의 내림차순으로 조회할 수 있다.
@Repository
public interface BoardRepository extends JpaRepository<Board, Long> {
@Query(value = "SELECT b FROM Board b")
List<Board> findBoardWithOutCount(Pageable pageable);
...
}
이전에 구현했던 리턴 타입을 List로 변경한 메서드이다.
이젠 다시 Board 엔티티의 PK를 토대로 데이터를 조회하는 메서드를 만들어보자.
@Repository
public interface BoardRepository extends JpaRepository<Board, Long> {
// @Query(value = "SELECT b FROM Board b")
// List<Board> findBoardWithOutCount(Pageable pageable);
List<Board> findByIdLessThanOrderByIdDesc(Long boardId, Pageable pageable);
...
}
이 방법은 굳이 쿼리문을 커스텀하지 않아도 된다. 보다시피 사용되는 쿼리문도 굉장히 간단하다.
SELECT *
FROM `board`
WHERE id < :가장 마지막으로 조회한 게시글의 ID
ORDER BY id DESC
LIMIT 10
이후 Repository 테스트를 진행했다.
@DataJpaTest
@ActiveProfiles("test")
class BoardRepositoryTest {
...
@Test
@DisplayName("Offset 없이 게시글 리스트를 조회한다.")
void findBoardListWithoutOffset() {
// given
Member member = createMember();
memberRepository.save(member);
List<Board> boards = new ArrayList<>();
for (int i = 1 ; i <= 20 ; i++) {
boards.add(createBoard("제목 " + i, "내용 " + i, member));
}
boardRepository.saveAll(boards);
// when
Pageable pageable = PageRequest.of(0, 10);
List<Board> fistPage = boardRepository.findByIdLessThanOrderByIdDesc(21L, pageable);
List<Board> lastPage = boardRepository.findByIdLessThanOrderByIdDesc(11L, pageable);
// then
assertThat(fistPage).hasSize(10);
assertThat(lastPage).hasSize(10);
assertThat(fistPage.get(0).getTitle()).isEqualTo("제목 20");
assertThat(fistPage.get(9).getTitle()).isEqualTo("제목 11");
assertThat(lastPage.get(0).getTitle()).isEqualTo("제목 10");
assertThat(lastPage.get(9).getTitle()).isEqualTo("제목 1");
}
}

테스트가 정상적으로 통과되었다.
서비스 코드도 약간의 수정이 필요하다.
@Service
@RequiredArgsConstructor
public class BoardServiceImpl implements BoardService {
private final BoardRepository boardRepository;
...
@Override
public List<BoardListServiceResponse> findAllBoard(Long boardId) {
Pageable pageable = PageRequest.of(0, 10);
List<Board> all = boardRepository.findByIdLessThanOrderByIdDesc(boardId, pageable);
return all.stream()
.map(board -> BoardListServiceResponse.builder()
.board(board)
.build())
.toList();
}
}
No Offset을 적용한 뒤 두 방식의 실행시간을 비교해봤다.
No Offset을 적용하기 전 가장 마지막 페이지를 조회한 결과
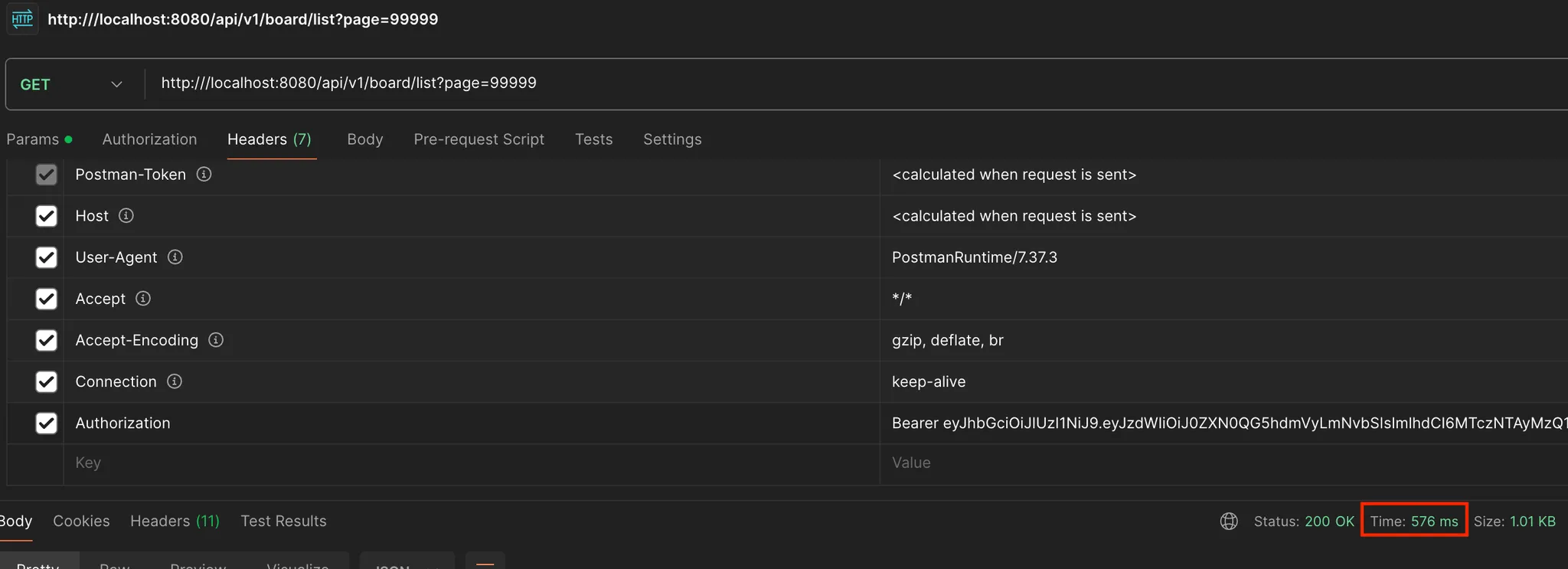
No Offset을 적용한 후 마지막 페이지를 조회한 결과

실행 시간이 576ms에서 214ms로 단축되었다.
참고로 No Offset은 정말 많은 양의 데이터를 조회하는 서비스(페이스북, 인스타 등등..)에서 사용하면 좋은 방법인 듯 하다.
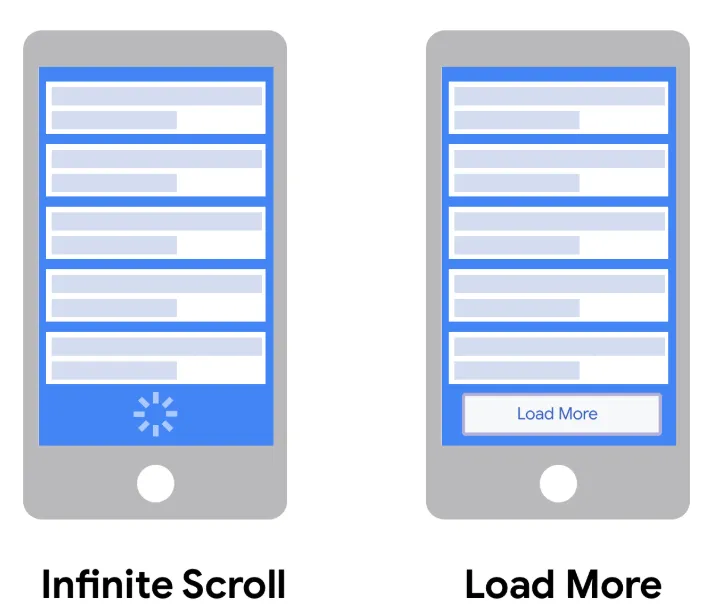
왜냐하면 아래와 같은 이미지의 UI는 구현이 불가능해지기 때문이다.

페이스북과 인스타같이 아래로 드래그를 하거나 Load More 버튼을 클릭하여 아래의 게시물을 조회하는 방식만 사용할 수 있다.
참고
https://jojoldu.tistory.com/528?category=637935
https://addyosmani.com/blog/infinite-scroll-without-layout-shifts/
'Spring > JPA' 카테고리의 다른 글
| [JPA] 여러 트랜잭션이 하나의 영속성 컨텍스트? (0) | 2024.07.31 |
|---|---|
| [JPA] @Embedded, @Embeddable (0) | 2024.07.16 |